
Accio ligas chidas ⚡🤓
Accio ligas chidas ⚡🤓
🎧 Los Tigres del Norte - Por Tu Maldito Amor


Esta imagen no tiene nada que ver con este boletín pero se ve chida como portada cuando lo compartas en tus redes sociales 😎
¡Pásele! ¡Pásele! ¡Pásele!
Este boletín viene XL con toño, papel.
Tenemos conjuntos de datos, tenemos meetups, tenemos tutoriales, tenemos blogs, tenemos videos, tenemos apps, tenemos becas, tenemos notícias. Antes de comenzar les recuerdo que este recurso sale cada semana y que es súper fácil inscribirse en tacosdedatos.substack.com o dándole clic en este botón
pa’ que se lo compartan a sus amiguis.
Grupos
Lesly Zerna aka @leslysandra esta organizando el Meetup TensorFlow User Group Bolivia en Sucre: más info en la página https://www.meetup.com/TensorFlow-User-Group-Bolivia/
En Guanajuato, México va a haber un Meetup sobre crear aplicaciones web Serverless con AWS Amplify y AWS AppSync este sábado 14 de marzo 2020: más info en la página https://aplicacionesserverlessaws.splashthat.com/
En el internet, Don Pandas aka Wes McKinney anunció un grupo para desarrolladores de proyectos de datos. Este grupo es para conectar con otras personas que puede que estén haciendo proyectos similares pero en otros lenguajes. Vale la pena mencionar que Wes McKinney de junto con Hadley Wickham (creador del tidyverse) para crear Ursa Labs quienes están desarrollando Arrow para manejar datos entre lenguajes de manera eficiente. Aquí el discord: discuss.ossdata.org


Hablando de grupos chidos que cambien vidas, las PyLadies de Ciudad de México tuvieron un taller introductorio a Python para datos y obvis microbis compartieron el repositorio de GitHub. Denle estrellita y manden buenas vibras: https://github.com/mar-esther23/CursoPandas2020
Datos, datos y más datos
Tu qué sabes de Big Data si nunca haz trabajado con datos climatológicos.


La pandilla de Pangeo anunciaron un nuevo dataset masivo (el primer paso es descargar una parte del conjunto total de datos y esa parte es 175 gb 🤯). El conjunto de datos viene con un reto para crear un modelo de inteligencia artificial que ayude a predecir el clima. Si te asustaste con lo de 175 gb no te preocupes porque el repositorio de GitHub viene con un enlace al BinderHub especial de Pangeo que tiene capacidades computacionales increíbles y es de uso gratuito. Sigue los enlaces del tuit para aprender más de esto.
Hablando de datasets masivos, en Londres existe un mercado llamado Tesco 411 del cual acaban de publicar los datos para 420 millones de productos alimenticios comprados por 1.6 millones de clientes. Cada producto viene con su contenido calórico e información de su valor nutricional. Este tipo de datos tan granulares permite explorar tendencias culturales y del factor socioeconómico ya que puedes conectarlo a áreas geográficas también 🤯 más aquí https://www.nature.com/articles/s41597-020-0397-7
Otro conjunto de datos súper interesante que me encontré esta semana es este de PUDL (no el perro - Public Utility Data Liberation project). Esta gente de PUDL limpiaron, homologaaron y publicaron datos que se encontraban previamente libres pero en un formato no accesible para el análisis a gran escala. Publicaron también los scripts que usan para limpiar y homologar los datos: https://github.com/catalyst-cooperative/pudl
Curiosamente, en su sitio web anuncian que están disponibles para ser contratados para el análisis de estos mismos datos. Esto se me hace un modelo de negocios muy interesante que tal vez valga la pena explorar en Latinoamérica: trabajas con datos abiertos, los limpias y públicas para que cualquier persona los use pero como eres la organización experta todavía traes valor agregado y vale la pena contratarte ? 🤔🤔🤔
¯\_(ツ)_/¯
Hablando de cosas interesantes, este conjunto de datos es sobre los imperios que han existido en la historia de la humanidad e incluye información de los países actuales que existen en dónde estos imperios alguna vez lo hicieron: https://www.wnvermeulen.com/empires/
¿Quién se avienta unos mapas bien chidos con ese? 👀👀
Hablando de datos geográficos, una herramienta más para trabajar con ellos: Gimme Geodata http://hanshack.com/geotools/gimmegeodata/
Gimme Geodata te da acceso rápido a datos de OpenStreetMap simplemente dándole clic a un mapa en el navegador. Esto me encanta, personalmente, porque nunca puedo encontrar Tijuana, mi ciudad, en OSM por la etiqueta que utilizan. Si le hago clic a Tijuana en este mapa descubro que tengo que buscar “Municipio de Tijuana” no solo “Tijuana” para accesar los datos -____-
Para acabar esta sección les dejo esta conferencia de datos abiertos en Latinoamérica que tomará lugar este septiembre en Panamá


Blogs y libros
Si te suscribiste a este boletín en español y sigues @tacosdedatos lo más probable es que lo que estés buscando es contenido en español. Trato de encontrar contenido en español pero la verdad hay veces que no encuentro suficiente para llenar un boletín entero. Lo bueno es que hay contenido como este que es una traducción de un blog en inglés al español publicado en Ciencia y Datos en Medium: “Aprendizaje No Supervisado Desmitificado” https://link.medium.com/daSb5k8p63
Muchas veces quienes queremos empezar a crear contenido en español queremos comenzar de cero pero igual de valioso es traducir contenido ya creado de otros idiomas al español para que nosotrxs también tengamos acceso a esa información.
Este siguiente no está en español jajajaja perdón 😔
Este artículo se títula Pensamiento Estadístico para el Cientifico del Siglo XXI y está muy interesante para quiénes estamos bien nerdamente interesados en los conceptos estadísticos detrás de esa magia negra que llamamos inteligencia artificial: https://advances.sciencemag.org/content/3/6/e1700768.full
Hablando de cosas nerds, econometría. Hace poco tuvimos una serie de seminarios en la oficina dónde un camarada presentó un mini curso de econometría para quiénes vamos empezando. Estuvo muy interesante pero quería verlo en práctica así que busque recursos de econometría en R y python. Este es uno de ellos: Econometrics with R: El repo https://github.com/mca91/EconometricsWithR y su sitio web https://www.econometrics-with-r.org/
También encontré este repositorio con el código para reproducir las figuras del libro “Mostly Harmless Econometrics” en R, python, stata y Julia 😱
https://github.com/vikjam/mostly-harmless-replication
Notícias
Santander anuncia 2500 becas para estudiar un programa en línea de Liderazgo y Transformación Digital. Las aplicaciones cierran el 15 de marzo: https://www.becas-santander.com/es/program/becas-santander-for-mit-leading-digital-transformation
Y con esta noticia hubiera empezado el boletín pero la guarde hasta acá para quiénes en serio leen esto: Los premios Sigma anuncian los ganadores de este año
https://datajournalism.com/awards
Son los premios al periodismo de datos, yo diría, más importantes del momento y hay uno que otro medio latinoamericano que ganó 🙏🏼👀
Videos
La famosisisisima rstudio::conf 2020 acaba de acontecer en San Francisco, California y ya están en línea los videos de las charlas presentadas en su sitio web https://resources.rstudio.com/rstudio-conf-2020
Entre mis favoritos:
Pequeño equipo, gran valor: Usando R para diseñar visualizaciones
El desarrollo de “datos” el paquete de R para Ciencia de Datos en español
Y este vídeo no viene de RStudio conf sino de Antonio Feregrino quien acaba de publicar dos artículos en tacosdedatos.com y es sobre cómo usar Git en equipo:
Y para acabar
Herramientas
La app Carnets te permite crear y ejecutar jupyter Notebooks en tu dispositivo iOS 🤯 y utiliza tu cuenta de iCloud para sincronizarlos en todos tus dispositivos así que si tienes una laptop Macbook puedes crear Notebooks desde tu celular y luego verlos en tu computadora 😱
https://holzschu.github.io/Carnets_Jupyter/
Algo similar en Android es pydroid 3 que hasta donde yo entiendo te da una terminal donde puedes instalar jupyter y ejecutar el comando
jupyter notebook
les dejo este tuit donde aprendimos como lo pueden instalar de la manera correcta (jupyter)



Ahí mismo en tuiter encontré este consejo de R que ya se me hizo casi casi tradición compatir en este boletín:

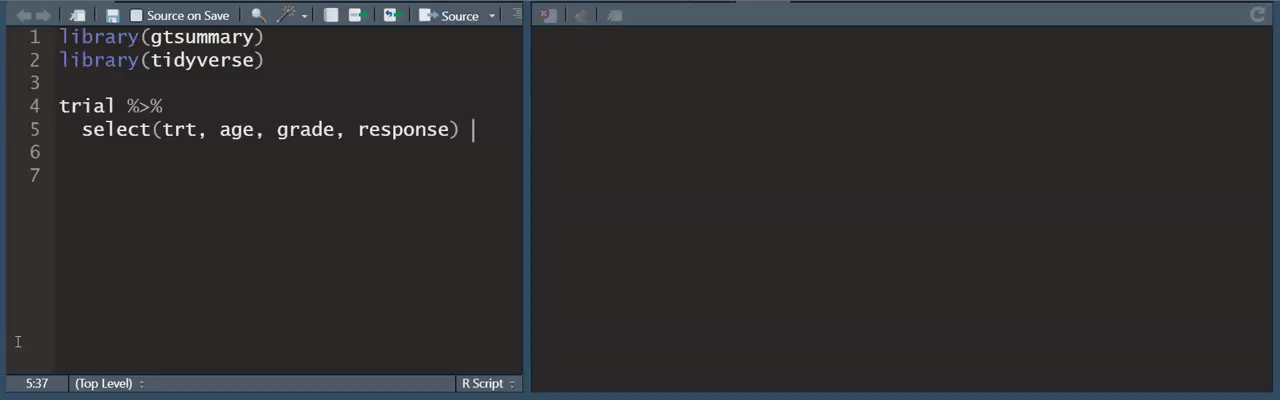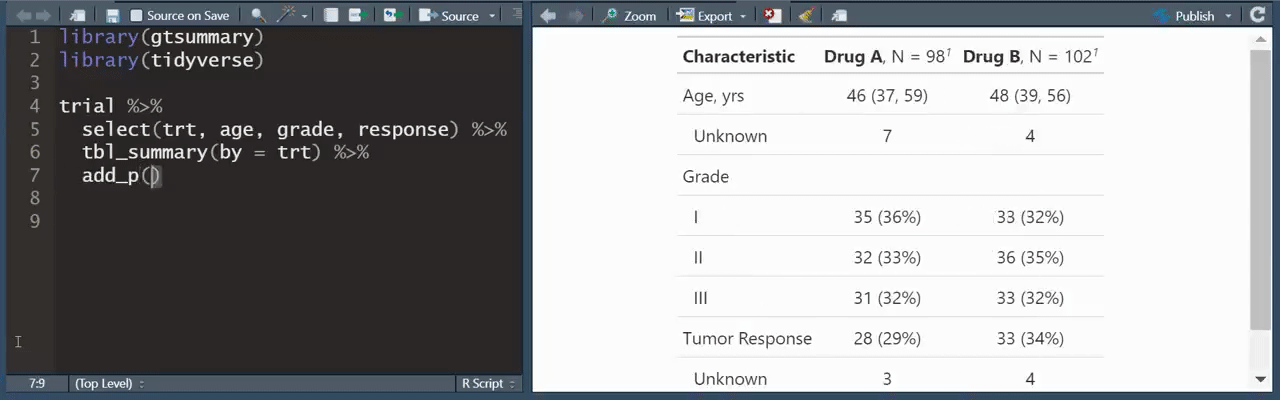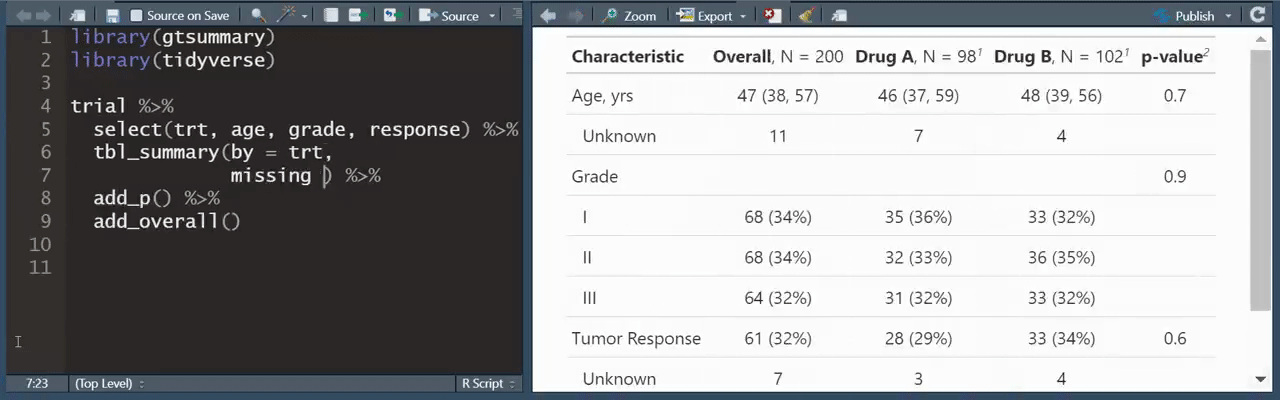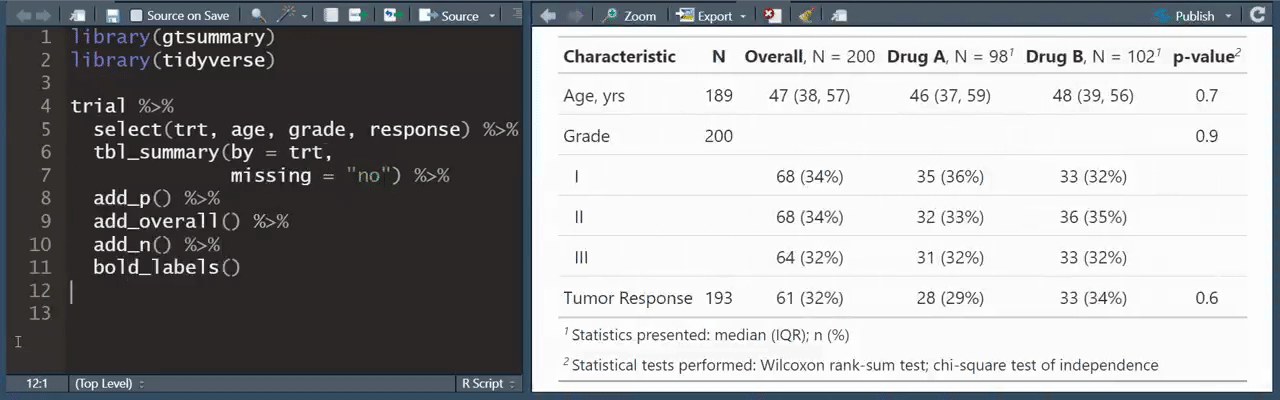
Y hablando de Twitter, ¿alguna vez has intentado adquirir datos de ahí? es todo un show el registrarte, registrar tu app, etc etc. twint es una herramienta para “scrappear" twitter sin tener que hacer eso 👌🏼
https://github.com/twintproject/twint
La última herramienta que les voy a compartir es el Data Kit de la Associated Press. Esta es una herramienta de la línea de comandos para organizar tus proyectos de periodismo de datos. Facilita la estandarización y el compartir de proyectos. Tembien te integra el guardar datos en la nube si sabes hacer eso 🤓
DataKit utiliza cookiecutter detrás de escenas para crear un proyecto. Si te interesa, yo compatí en GitHub la plantilla que utilizo para todos mis proyectos de datos. Se encuentra aquí con todo e instrucciones:
https://github.com/tacos-de-datos/cookiecutter-analisis-de-datos
Bonus
Checa si tu sitio web es accesible para personas que no pueden ver todos los colores: https://www.toptal.com/designers/colorfilter/
Lo que ando consumiendo…
Talk Python To Me (podcast): #252 What Scientific Computing Can Learn From CS
Why Ancient Mapmakers Were Terrified of Blank Spaces (National Geographic)
La serie de Netflix Tijuana
Ya lo había compartido antes pero no puedo dejar de escuchar el nuevo disco de Los Tigres del Norte y específicamente la canción Acá Entre Nos (les juro que estoy bien nomás es una muy buena canción jajajaj)
Antes de despedirme…
Si llegaste hasta acá tal vez te interese mi boletín personal en el que estaré escribiendo más a fondo sobre distintos temas de política pública, datos, tecnología en Latinoamérica y especialmente de visualización de datos. Es de substack como este boletín. Este boletín va a seguir existiendo semanalmente para compartir recursos - el otro boletín es para investigar más a fondo ciertas noticias o tendencias desde un enfoque de los datos. Se llama Visualizin’ The Realism y se encuentra aquí: chekos.substack.com
Ahí escribiré en inglés y español ya que así piensa mi cerebro hoy en día jajaj
Muchísimas gracias por leer y compartir. tacosdedatos crece gracias a ti 🌮♥️
Te dejo este botoncito para suscribirte si no lo haz hecho
y este para compartir esta entrada del boletín👇🏼
y uno más para compatir tacosdedatos, el boletín
¡Hasta la próxima semana!
ay’tamos